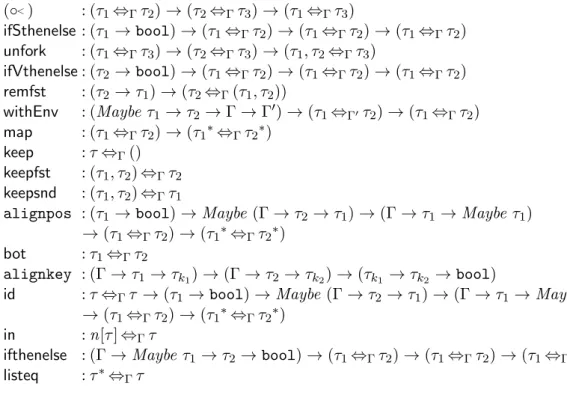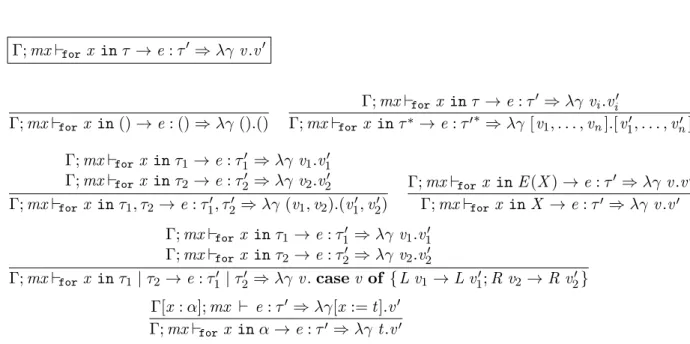ISSN 1884-0760
GRACE TECHNICAL REPORTS
BiFluX: A Bidirectional Functional Update
Language for XML
Hugo Pacheco Tao Zan
Zhenjiang Hu
GRACE-TR 2014-02 August 2014
CENTER FOR GLOBAL RESEARCH IN
BiFluX: A Bidirectional Functional Update
Language for XML
Hugo PACHECO Cornell University, USA [email protected]
Tao ZAN
The Graduate University for Advanced Studies, Japan [email protected]
Zhenjiang HU
National Institute of Informatics, Japan [email protected]
August 7th, 2014
Abstract
Different XML formats are widely used for data exchange and processing, being often necessary to mutually convert between them. Standard XML transformation languages, like XSLT or XQuery, are unsatisfactory for this purpose since they require writing a separate transformation for each direction. Existingbidirectional transformation
languages mean to cover this gap, by allowing programmers to write a single program that denotes both transformations. However, they often 1) induce a more cumbersome programming style than their traditionally unidirectional relatives, to establish the link between source and target formats, and 2) offer limited configurability, by making implicit assumptions abouthow modifications to both formats should be translated that may not be easy to predict.
1
Introduction
Nowadays, various XML formats are widely used for data exchange and processing. Since data evolves naturally over time and is often replicated among different applications, it becomes frequently necessary to mutually convert between such formats. However, traditional XML transformation languages, like the XSLT and XQuery standards of the World Wide Web Consortium (W3C), are unsatisfactory for this purpose as they require writing a separate transformation for each direction.
Bidirectional transformation (BX) languages [11] mean to cover this gap, by allowing users to write a single program that can be executed both forwards and backwards, so that consistency between two formats can be maintained for free. A variety of bidirectional languages have emerged over the last 10 years to support bidirectional applications in the most diverse computer science disciplines [11], including functional programming, software engineering and databases. These languages come in different flavors, including many focused on the transformation of tree-structured data with a particular application to XML documents [21, 7, 22, 12, 26, 13, 19], and can be classified into three main paradigms. The firstrelational paradigm [21, 7] prescribes writing a declarative (non-deterministic) consistency relation between two formats, from which a suitable BX is automatically derived. The second bidirectionalization paradigm [22, 12, 25] asks users to write a transformation in a traditional unidirectional language, that plays the role of a functional consistency relation. The lastcombinatorial paradigm [26, 13, 19] encompasses the design of a domain-specific bidirectional language in which each combinator denotes a well-behaved BX, allowing users to write correct-by-construction programs by composition.
As most interesting examples of BXs are not bijective, there may be multiple ways to synchronize two documents into a consistent state, intro-ducing ambiguity. Despite of this fact, bidirectional languages are typically designed to satisfy fundamental consistency principles, and support only a fixed set of synchronization strategies (out of a myriad possible) to translate a (non-deterministic) bidirectional specification —the syntactic description of a BX— into an executable BX procedure. This latent ambiguity often leads to unpredictable behavior, as users have limited power to configure and understand what a BX does from its specification. Even for combinatorial languages, that have the theoretical potential to fully specify the behavior of a BX [14, 28], their lower-level programming style requires significant effort and expertise from users to write intricate BXs via the composition of simple, concrete steps; they also scale badly for large formats, since one must explicitly describe how a BX transforms whole documents, including unrelated parts.
are kept consistent. As SQL stands for relational databases, a few high-level XML update languages [30, 15, 8] facilitate common modification operations over XML documents. Contrarily to XML transformation languages, XML update languages are well-suited for specifying smallin-place changes to in a concise way, leaving all the remaining parts of a document unchanged.
In this paper, we propose a novel bidirectional programming by update
paradigm, in which the programmer writes an update program that describes how to update a source model to embed information from a target model, and the system derives a query from source to target that evinces the consistency between both models. Such a bidirectional update allows to express the relationship between source and target models in a simple way —as in the relational paradigm— by saying which related source parts are to be updated, but combined with additional actions that supply the missing pieces to tame the ambiguity inhow target modifications are reflected —as in the combinatorial paradigm. For a wide class of BXs usually known as lenses [14], that have a data flow from source to view, this paradigm opens a new axis in the BX design space that enjoys a unique tradeoff between the declarative style of relational approaches and the stepwise style of combinatorial approaches. This paper demonstrates that a new family of
bidirectional update languages, featuring an hybrid programming style, can render bidirectional programming more user friendly.
From a linguistic perspective, the main contribution of this paper is conceptual: we propose the idea of extending an update language with bidirectional features to write, directly and at a nice level of abstraction, a view update translation strategy which bundles all the necessary pieces to build a BX. Concretely, we design BiFluX, a type-safe, declarative and expressive language for the bidirectional updating of XML documents that is deeply inspired byFlux [8], a simple and well-designed functional XML update language. We lift unidirectional Flux updates to bidirectional
BiFluXupdates by imbuing them with an additional notion of view. Reading updates as BXs will motivate a few language extensions to originalFlux, and require a suitable bidirectional semantics and extra static conditions on
BiFluXprograms to ensure that they build well-behaved BXs.
We demonstrate the usefulness ofBiFluXby illustrating typical examples of BXs written as bidirectional update programs. These help clarifying the stylistic differences to traditional bidirectional programming approaches, and substantiate that bidirectional update languages can combine a declarative language notation with a flexible and clear semantics. BiFluX has been fully implemented and tested with many examples including those in this paper.
The rest of the paper is organized as follows. After briefly explaining the novel features of BiFluXin Section 2, we show typical examples of BiFluX
bidirectional updates, and Section 5 discusses the static typing and semantics of coreBiFluX. Section 6 formalizes the translation from high-level to core
BiFluX, Section 7 compares our approach with related work on bidirectional and XML programming, and Section 8 concludes with a synthesis of the main ideas and directions for future work.
2
A Bidirectional Update Language
Before giving concrete examples in Section 3, we start with a brief explanation of the features of BiFluXand its informal semantics to show the big picture of our general framework.
2.1 BiFluX syntax
We define the high-level syntax of BiFluXin Figure 1 as a modest syntactic extension to Flux; the new features that are the focus of this paper are highlighted ingreen. Flux [8] is a high-level, purely functional language for writing XML updates, with a clear semantics and syntactic typechecking. Similarly, we typecheckBiFluX programs by translating them into a canon-ical core language with a clear bidirectional semantics. Our examples assume an informal familiarity with commonplace XML technologies like XQuery expressions, XPath paths and XDuce-style regular expression types.
To have a taste of BiFluX, imagine that we want to update the last author of a particular book with title ’Querying XML’ in a database of books with type
books[book[title[string],author[string]+]∗]
using a view of type author[string]. We can accomplish this by writing an update (with source $source and view $view):1
UPDATE $source/books/book BY { REPLACE author[last()] WITH $view } WHERE SOURCE title = "Querying XML"
Flux-like syntax At first glance, bidirectionalBiFluXprograms look just like regularFlux programs. We omit the syntactic definitions of expressions Expr, paths P ath, and patterns P at. Variables V ar are written $x,$y, etc. StatementsStmt include conditionals, composition, let-binding, case expressions or updates, which may be guarded by aWHEREclause that defines a set of conditions. Statements can be empty {} or parenthesized using braces{Stmt}. As inFlux,in-place updatesU pdcan besingular, to update
1
single trees, orplural, to update the children of each selected tree. Single insertions (INSERT BEFORE/AFTER) insert a value before or after each node selected by a path, while plural insertions (INSERT AS FIRST/LAST INTO) insert a value at the first or last position of the child-list of each selected node. Singular deletions (DELETE) delete each selected node, while plural deletions (DELETE FROM) delete their content. Single replacements (REPLACE WITH) replace each node selected by a path, while plural replacements (REPLACE IN) replace their content. Single updatesUPDATE BY apply a statement to each tree in the result of a path.
Source and view matching The main difference in BiFluX is that
updates on sources carry an additional notion of view, what becomes syn-tactically evident with a new non-in-place UPDATE FOR VIEW operation that synchronizes a source sequence with a view sequence. Such synchronization can be configured by the programmer via a matching condition that aligns source and view nodes, and a triple of matching/unmatching clauses that describe the actions for individual source-view nodes. When two source and view nodes MATCH, a bidirectional statement is executed to update the source using the view; an unmatched view node (UNMATCHV) creates a new node in the source, either as a default or according to a unidirectional CREATE statement that provides a fresh source node to be normally updated with the existing view node; an unmatched source node (UNMATCHS) is DELETEd by default, but we may KEEP it by providing a unidirectional statement describing how to invalidate the given WHERE SOURCE selection criteria. It is worth noting that while UPDATE FOR VIEW statements are intrinsically bidirectional, the same BiFluX syntax (e.g., DELETE) may be overloaded and denote either a bidirectional or a unidirectional update depending on the context. The rule is that allBiFluX statements are bidirectional, ex-cept inside UNMATCHSorUNMATCHVclauses. An example that puts all these features to use is illustrated later in Figure 3.
Stmt ::= U pd [WHERE Conds]|Stmt ;Stmt | {Stmt } | { } | IF T ag Expr THEN Stmt ELSE Stmt
| LET T ag P at=Expr IN Stmt
| CASE T ag Expr OF{ Cases }
U pd ::= INSERT(BEFORE|AFTER) P atP athVALUE Expr
| INSERT AS (FIRST |LAST) INTO P atP athVALUE Expr
| DELETE[FROM]P atP ath |REPLACE [IN]P atP ath WITH Expr
| UPDATEP atP ath BY Stmt
| UPDATEP atP ath BY V StmtFOR VIEW P atP ath[M atch] | KEEP P atP ath |CREATE VALUEExpr
Conds ::= T ag Expr [;Conds]|T ag V ar :=Expr [; Conds]
Cases ::= P at → Stmt |Cases ′|′ Cases
V Stmt ::= { V Stmt } | V U pd
| V U pd ′|′ V U pd
V U pd ::= MATCH → Stmt
| UNMATCHS →Stmt
| UNMATCHV →Stmt M atch ::= MATCHING BY P ath
| MATCHING SOURCE BY P ath VIEW BYP ath
P atP ath ::= [P at IN]P ath
T ag ::= [SOURCE|VIEW]
Figure 1: Concrete syntax of BiFluXupdates.
Source/view/normal expressions Our language considers three kinds
of source, view or normal variables. Expressions inIF,LET,CASE orWHERE clauses support additional tags to disambiguate if they refer to only the SOURCE, to only the VIEW, or to the global environment of an update. These tags can be ignored at first glance and will in fact be omitted in our examples, as they are inferable from context information for each update. Update procedures are omitted but can be easily added to the language.
2.2 Informal semantics and general framework
In general, aBiFluX update is executed for a particular source and view as follows: a source path is evaluated over the current source, yielding a
source focus selection, to be recursively updated using a view focus selection
computed by evaluating a view path over the current view, until all the view information is embedded into the source. View and source focus selections denote the mutable parts of the source and view trees that can be updated and used by the update, and subexpressions of the update may restrict the focuses.
U(s, v′) =s′ that updates a sourcesinto a new source s′ which contains a
given viewv′, or 2) aquery function Q(s) =v that computes a viewv from a given source s; these functions may be partial2. For the example at the beginning of this section, (assuming that books are uniquely identified by their titles) the corresponding query function is semantically equivalent to the XPath expression that returns the last author of the respective source book:
$source/books/book[title="Querying XML"]/author[last()]
Our language is carefully designed to ensure that the inferred relationship between sources and views is deterministic, so that capturing it by a query function is appropriate. In other words, there exists a unique query function for each update program written in our language. Moreover, its bidirectional semantics satisfies two basilar synchronization properties; that an updateU consistently embeds view information to the source, without view side-effects:
U(s, v′) =s′ ⇒ Q(s′) =v′ UpdateQuery
and that it does not update already consistent sources:
Q(s) =v ⇒ U(s, v) =s QueryUpdate
These two properties are commonly known as the well-behavedness laws of lenses in the bidirectional programming community [11].
For an example of a Fluxupdate that is not (syntactically) valid as a
BiFluXupdate, imagine that we had written instead:
UPDATE $source/books/book BY {
INSERT AS LAST INTO author VALUE $view } WHERE SOURCE title = "Querying XML"
This update function is not idempotent on sources, since it always inserts the view as an extra author of the source book, violatingQueryUpdate: even when the view is already an author of the source book, a new du-plicated author is inserted. Such class of valid BiFluX updates can be statically checked, namely as the programs for which update normalization and typechecking succeed.
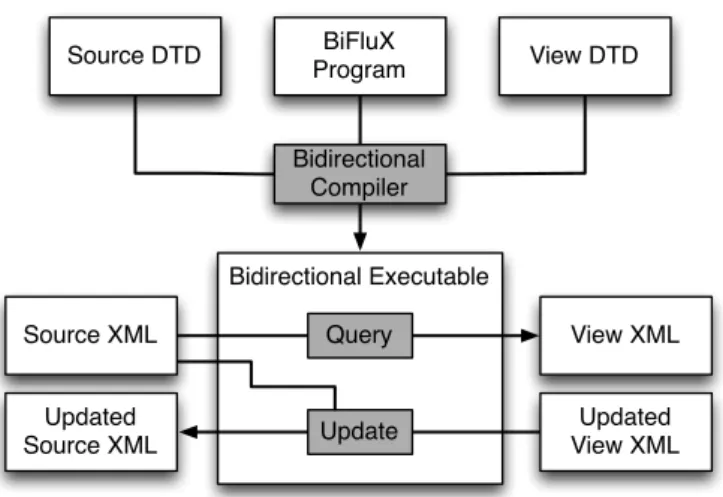
The general architecture of our bidirectional updating framework is illustrated in Figure 2. ABiFluXprogram is evaluated in two stages. First, it is statically compiled against a source and a view schema (represented as DTDs), producing a bidirectional executable. The generated executable can then be evaluated bidirectionally for particular XML documents conforming to the DTDs: in forward mode as a query Q, or in backward mode as an updateU.
2
Bidirectional Executable
Query
Update BiFluX Program
Source DTD View DTD
Updated Source XML
View XML
Updated View XML Source XML
Bidirectional Compiler
Figure 2: Architecture of theBiFluX framework.
PROCEDURE niibook(SOURCE $source AS s:addrbook, VIEW $view AS v:niibook) = UPDATE $source/addrbook/person BY {
MATCH -> REPLACE email[ends-with(text(),’nii.ac.jp’)][1] WITH $email’
| UNMATCHV -> CREATE VALUE <person> <name/> <tel>+81-3-4212-2000</tel> </person> | UNMATCHS -> KEEP . ; DELETE email[ends-with(text(),’nii.ac.jp’)]
} FOR VIEW employee[$name AS v:name, $email’ AS v:email] IN $view/niibook/employee MATCHING BY name WHERE email[ends-with(text(),’nii.ac.jp’)]
Figure 3: BiFluXupdate for the institutional address book example.
3
Examples
This section illustrates how writing a bidirectional update feels like to a programmer, through a series of BX examples usingBiFluX:
Example 3.1 demonstrates how the new bidirectional notation, in com-bination with ordinary unidirectional Flux updates, can intuitively describe a bidirectional update;
Example 3.2 illustrates nested bidirectional updates and flexible non-local matching behavior;
Example 3.3 showcases pattern matching and recursive procedures.
3.1 Institutional address book example
<!DOCTYPE addrbook [
<!ELEMENT addrbook(person*)>
<!ELEMENT person(name,email*,tel?)> <!ELEMENT name(#PCDATA)>
<!ELEMENT email(#PCDATA)> <!ELEMENT tel(#PCDATA)> ]>
Figure 4: A simple address book DTD.
<addrbook><person><name>Hugo Pacheco</name> <email>[email protected]</email>
<email>[email protected]</email></person> <person><name>John Doe</name>
<email>[email protected]</email></person>
<person><name>Zhenjiang Hu</name><email>[email protected] </email><tel>+81-3-4212-2530</tel></person>
</addrbook>
On the other hand, the NII’s administrative services may keep only a view with the name and institutional address of employees (people with an email at ”nii.ac.jp”), as shown in the DTD from Figure 5.
We can easily write a bidirectional update inBiFluXto synchronize these two formats, as illustrated in Figure 33. The root procedure niibook takes
as arguments the root source and view variables. It focuses on a sequence of source persons by traversing down the path $source/addrbook/person, selecting only those that have NII emails, and focuses on a sequence of view employees by traversing up the (injective) path $view/niibook/employee. Elements in the two sequences are matched by their names. For matching person-employee pairs, the person’s first NII email is updated with the employee’s email. If a new unmatched employee exists in the view, a new person with a default telephone is created in the source (inheriting its view name and email). If an old unmatched person exists in the source, all its NII emails are deleted.
The unique query for this example simply keeps the first institutional email of each person working at the NII:
<niibook><employee><name>Hugo Pacheco</name> <email>[email protected]</email></employee> <employee><name>Zhenjiang Hu</name>
<email>[email protected]</email></employee> </niibook>
The update function is more interesting. For instance, if we add Tao (in alphabetical order) as a new NII employee, fix Zhenjiang’s email and delete Hugo, we get an updated source where John is left unchanged, Tao is created
3
<!DOCTYPE niibook [ <!ELEMENT niibook (employee*)> <!ELEMENT employee (name,email)>
<!ELEMENT name (#PCDATA)> <!ELEMENT email (#PCDATA)> ]>
Figure 5: A NII address book DTD.
PROCEDURE socialbook(SOURCE $source AS s:addrbook, VIEW $view v:socialbook) = UPDATE $source/addrbook/group BY { MATCH ->
UPDATE $person IN $persons BY { MATCH -> {}
| UNMATCHV -> LET $old = $source/addrbook/group/person IN
LET $oldperson = $old[name/text() = $person’/name/text()][1] IN IF $oldperson THEN CREATE VALUE $oldperson ELSE {}
} FOR VIEW $person’ IN $persons’ MATCHING BY name } FOR VIEW group[$name AS v:name, $persons AS v:person*]
IN $view/socialbook/group MATCHING BY name
Figure 6: BiFluXupdate for the social address book example.
with a default telephone number (as his name does not match any name in the original source), Zhenjiang’s NII email is updated and the NII email of Hugo is deleted:
<addrbook><person><name>Hugo Pacheco</name> <email>[email protected]</email></person> <person><name>John Doe</name>
<email>[email protected]</email></person>
<person><name>Tao Zan</name><email>[email protected] </email><tel>+81-3-4212-2000</tel></person>
<person><name>Zhenjiang Hu</name><email>[email protected] </email><tel>+81-3-4212-2530</tel></person>
</addrbook>
Note that if we queried the updated address book again, we would get a view with the names and NII emails of only Tao and Zhenjiang.
As a BX side note, this precise behavior can not be achieved using the existing typical declarative BX languages, which are not designed with fine user control in mind; alignment-aware combinatorial BX languages could be tailored to produce similar behavior, but getting it right requires much higher effort and expertise.
3.2 Social address book example
<!DOCTYPE html[<!ELEMENT html(head,body)> <!ELEMENT head (#PCDATA)>
<!ELEMENT body (h1,dl)> <!ELEMENT h1 (#PCDATA)> <!ELEMENT dl ((dt|dd)*)> <!ELEMENT dt (a)>
<!ELEMENT a (href,#PCDATA)> <!ELEMENT dd (h3,dl)> <!ELEMENT h3 (#PCDATA)> ]>
Figure 7: A Netscape bookmark format DTD.
addrbook[group[name[string],person[. . .]∗]∗]
Consider our address book with people now classified into groups:
<addrbook><group><name>coworkers</name>
<person><name>Hugo Pacheco</name>...</person>
<person><name>Zhenjiang Hu</name>...</person></group> <group><name>friends</name><person>
<name>John Doe</name>...</person></group> </addrbook>
This time, a social media application may only be interested in the groups and names of people, according to a view schema:
socialbook[group[name[string],person[name[string]]∗]∗]
A bidirectional update that synchronizes address and social books is written in Figure 6. It starts by matching groups, proceeding recursively for persons within groups (with default behavior for unmatched groups). Inside, for source-view persons matching on their name, no update is necessary. For each unmatched view person, we attempt to retrieve its address book information from any other group in the original source, or otherwise create a default person.
The corresponding query function produces a view with the same structure but showing only names of groups and persons. For the update function, imagine that we modify the view by reordering the two groups, changing Hugo’s group and creating a new group for family members:
<addrbook><group><name>friends</name>
<person><name>Hugo Pacheco</name></person></group> <group><name>coworkers</name><person>
<name>Zhenjiang Hu</name></person></group> <group><name>family</name></group>
</addrbook>
PROCEDURE top(SOURCE $html AS s:html,VIEW $xbel AS v:xbel) =
UPDATE html[head[String], body[$h1 AS s:h1, dl[$nc AS (s:dt|s:dd)*]]] IN $html BY { REPLACE IN $h1 WITH $t ; contents($nc,$xc) }
FOR VIEW xbel[title[$t AS String], $xc AS (v:bookmark|v:folder)*] IN $xbel
PROCEDURE contents(SOURCE $nc AS (s:dt|s:dd)*,VIEW $xc AS (v:bookmark|v:folder)*) = UPDATE $nc BY { CASE $v OF {
bookmark[href[$url AS String], title[$title AS String]] -> REPLACE . WITH <dt><a><href>{$url}</href>{$title}</a></dt>
| folder[title[$title AS String], $fxc AS (v:bookmark|v:folder)*] -> REPLACE IN h3 WITH $title ; contents(dl/*,$fxc)
} } FOR VIEW $v IN $xc
Figure 8: BiFluXupdate for the bookmark example.
<addrbook><group><name>friends</name>
<person><name>Hugo Pacheco</name>...</person> <person><name>John Doe</name>...</person></group> <group><name>coworkers</name><person>
<name>Zhenjiang Hu</name>...</person></group> <group><name>family</name></group>
</addrbook>
Since Hugo changed from group coworkers to friends, he is considered an unmatched view person under his new group. Our bidirectional update avoids his original address details to be lost, by looking them up in all groups, instead of only in Hugo’s original group (what would be the default behavior). An analogous example motivates an extension to the alignment-aware language of [1].
3.3 Bookmark example
For a different bidirectional updating example, consider the conversion between two popular browser bookmark formats studied in [21]. Netscape stores its bookmarks in an HTML format (Figure 7), while the XBEL open XML bookmark exchange format opts for a loosely equivalent representation (Figure 9). Both formats contain a general title (h1ortitle) and a sequence of bookmarks (dtorbookmark) or folders (ddor folder), where folders may recursively contain sequences of bookmarks or folders.
The original biXid transformation [21] relies on pattern matching to decompose the source and target formats and can be replicated in BiFluX
as shown in Figure 8. The top procedure decomposes the source intohead
andbody (with a title $h1 and a sequence $ncof dts ordds) and the view into a title $t and a sequence $xc of bookmarks or folders. Then top
<!DOCTYPE xbel[<!ELEMENT xbel(title,(bookmark|folder)*)> <!ELEMENT title(#PCDATA)><!ELEMENT bookmark(href,title)> <!ELEMENT folder(title,(bookmark|folder)*)> ]>
Figure 9: A XBEL bookmark format DTD.
source and view bookmarks and folders: for a viewbookmark, we generate a sourcedt element with the bookmark’s href andtitle; for a view folder, we generate a source dd element with the folder’s title and a dl with recursively computed contents.
Finally, we can run our BiFluX program as a query that converts from Netscape to XBEL, or as an update that converts from XBEL to Netscape. This is not the best showcase example of BiFluX, since the source and view bookmarks are almost in bijective correspondence and there is small ambiguity to mitigate in the update. Nonetheless, note that ourBiFluX
program will preserve the original Netscape header, while the analogous biXid program would simply generate default data for unrelated parts.
4
Core Language
The high-level language presented in the previous sections follows a verbose and natural syntax that is convenient for users, but its operations are overlapping, complex and hard to typecheck. Following the design of Flux
and as standard for many other languages, we introduce a core update language of canonical operations whose semantics and typing rules are easier to define and manipulate.
4.1 XML values and regular expression types
As several other XML processing languages [17, 8, 9], we consider a type system of regular expression types with structural subtyping4:
Atomic types α::=boolkstringkn[τ]
Sequence types τ ::=αk()kτ |τ′ kτ, τ′ kτ∗kX
Atomic types α ∈ Atom are primitive booleans, strings or labeled sequences
n[τ]. Sequence typesτ ∈ Type are defined using regular expressions, including empty sequence (), alternative choice τ | τ′, sequential composition τ, τ′, iteration τ∗ or type variables X; choice and composition are right-nested. We define the usualτ+=τ, τ∗ andτ?=τ |(). Types can also be recursively
defined:
4
Type definitions τD::=αk()kτD |τD′ kτD, τD′ kτD∗
Type signatures E ::= · kE,typeX =τD
Type definitions τD are sequences with no top-level variables (to avoid
non-label-guarded recursion [9]). A type signature E is a set of named type definitions of the formX =τD, and is well-formed if no two types have the
same name and all type variables in definitions are declared inE. We write
E(X) for the type bound to X inE. Hereafter, we will assume the signature
E to be fixed.
In traditional XML-centric approaches [17, 9], values are encoded using a uniform representation that does not record the structure that types impose on values. This “flat” representation is economical and simplifies subtyping, but makes it harder to realize that a value belongs to a type and therefore to integrate regular expression features into functional languages with non-structural type equivalence, such as Haskell or ML. In this paper, we instead consider a structured representation of values (in line with values of algebraic data types) that keep explicit annotations which, in a way, witness how to parse a flat value as an instance of a type [23]:
Atomic values t ::=true|false|w |n[v]
Forest values v::=t |()|L v |R v |(v,v)|[v0, . . . ,vn]
Atomic values t ∈ Tree can be true,false ∈ Bool, strings w ∈ Σ∗ (for some alphabet Σ), or singleton treesn[v] with a node label n. Forest values v ∈ Val include the empty sequence (), left- L v or right- R v tagged choices, binary sequences (v,v) and lists of arbitrary length [v0, . . . ,vn].
The semantics of a type τ denotes a set of valuesJτKthat is defined as the minimal solution (formally the least fixed point [17]) of the following set of equations:
JboolK , {true,false} Jn[τ]K , {n[v]|v ∈ JτK}
JstringK , Σ∗ JXK , JE (X)K
Jτ, τ′K , {(v,v′)|v ∈ JτK,v′ ∈ Jτ′K} J()K , {()}
Jτ |τ′K , {L v |v ∈ JτK} ∪ {R v |v ∈ Jτ′K}
Jτ∗K , {[v0, . . . ,vn]|v0, . . . ,vn ∈ JτK,n > 0}
In our context, values in the type semantics preserve the type structure. We will denote flat valuesft ∈ FTree andfv ∈ FVal (dropping left/right tags, parenthesis and list brackets) by:
Flat atomic values ft ::=true|false|w |n[fv] Flat forest values fv::= ()|ft,fv
4.2 Core expression, path and pattern language
InBiFluX, updates instrumentally use XQuery expressions, XPath paths and XDuce patterns to manipulate XML data. This subsection succinctly describes their syntax in our core language, but is not essential for our design and may be skipped on a first reading.
We write expressions e in a minimal XQuery-like language that is a variant of the µXQ core language proposed in [9]:
e::= ()|e,e′|n[e]|letpat =e ine′ |p |e≈e′
| ife thene′ elsee′′|forx inereturne′
Despite expressions can be used in updates rather indiscriminately, in
BiFluXonly a particular subset of the expression language is suitable for denoting foci. Therefore, we differentiate paths p in a core path language that represents a minimal dialect of XPath:
p ::=self|child|dos| ::nt |wheree|p/p′
| x |w |true|false|F(~e)
nt::=n |text()|node()
To simplify the formal treatment, we consider nodetests ::nt that apply to atomic values and where clauses where e that filter values satisfying an expression e. We write the syntactic sugar p ::nt , p / ::nt and
p[e] , p/wheree. XPath-like traversals can be defined as.=self::node(),
p/n , p/child::a and p//n =p/dos::node()/child::a.
In contrast to µXQ, our core expression language supports pattern ex-pressions in let bindings: letpat =e ine′ matches a pattern pat against the result of an expression e and then executes an expression e′ that may refer to the variables bound by pat. We consider a language of XDuce-style
patterns pat [17]:
pat::=x asτ |τ |()|n[pat]|pat,pat′
Note that we impose a simple but strong syntacticlinearity restriction on patterns (no alternative choice, no Kleene star) to ensure that matching a value against a pattern binds each variable exactly once. Less severe linearity restrictions are actually known [16], but these simple patterns suffice for our practical needs. Also worth noting is that we require every variable to be annotated with a type. This simplifies our design, but will in turn increase the number of (often unnecessary) annotations in our bidirectional update programs. We see it as an orthogonal problem that can be mitigated using existing tree-based type inference algorithms [32].
4.3 Tripartite environments
usual, we assume variable names in an environment to be distinct. We write Γ(x) and γ(x) for the type and value of a variable; Γ[x:τ] andγ[x:=v] add a new variable to an environment. We say thatγ has type Γ, writtenγ: Γ, ifγ(x) : Γ(x) for all x ∈ dom(Γ). Fresh environments are denoted by the empty set∅.
Since our language is bidirectional, we will consider three kinds of vari-ables (and environments): source variables, that are accessible from the current source; view variables, that are accessible from the current view; andnormal variables, that are accessible from the global environment of the update and independent from the source or the view. We will talk about source/view/normal paths or expressions, that may only refer to source variables, view variables or any variable, respectively;non-source expressions may refer to view and normal variables simultaneously.
To describe source or view environments, we introduce record types ν that denote sequences of variable-annotated types:
ν::=x:τ, ν |()
As an abuse of notation, we see a record type ν as an ordinary type (by forgetting variable names) or as a type environment; we cast a conforming value v into an environmentγv:ν.
4.4 Core update language
Unlike conventional XML update languages, our core update language com-prises two kinds of update statements: unidirectionalFlux updates, inter-preted asarrows [20] that modify a document in-place, changing its schema; and bidirectional BiFluXupdates, interpreted as BXs [28] that update a source document given a view document or query a source document to compute its view fragment, for fixed source and view schemas. Our core
unidirectional updates uare adapted from the coreFluxupdate language [8]:
u::=skip|u;u′ |inserte|delete
| ifethenuelseu′ |caseeofpat~ →~u
| p[u]|left[u]|right[u]|children[u]
These include standard operations such as the no-opskip, sequential compo-sition, conditionals or case expressions. The basic operations are inserte, that inserts a value given an empty sequence as focus; and delete, that replaces any value with the empty sequence. We can also apply an update in a specificdirection (that traverses down a path p, moves to theleft or
rightof a value, or focuses on the childrenof a labeled node). Corebidirectional updates b are denoted by the grammar:
b::=skip|fail|b1;b2|viewx :=e inb
| ifSethenbelseb′ |caseSp ofpat~ →~b
| ifVethenbelseb′ |caseVeofpat~ →~b
| ifethenbelseb′ |caseeofpat~ →~b
| alignposes b c r |alignkeyes ps pv b c r
Here, P is the name of a BiFluX procedure. A procedure is defined as a declaration P(~x :~τ) :νs⇔νv , s, meaning that P takes a vector of
parameters~x of types~τ and builds a BX between a source of typeνs and
a view of type νv. Accordingly, a procedure call P(p~s, ~ev, ~e) takes three
kinds of arguments: source pathsp~s; non-source expressionse~v; and normal
expressions~e. We collect procedure declarations into a set ∆, that we will assume to be fixed. Procedures may also be recursive.
The bidirectional operation skip keeps the source unchanged for an empty view; for a non-empty view, we must fail to update the source (as UpdateQuery precludes that all view information must be used to update the source). Compositionb1;b2 updates the source withb1, and then
runsb2 over the updated source. The statementviewx:=einb models a
view dependency, by stating that a view variable x can be computed using the view expressione (written $x:=ein the high-level BiFluXlanguage), and then runs b using the remaining view. Bidirectional statements may also change the current source or view, by focusing down a source path and updating the resultant source (p[b]), or by evaluating a non-source expression “backwards” from the view and updating the source with the resultant view ([b]e). The basic replace operation embeds the view into the source, while
iterb embeds the same view into each tree in a source forest. As before, we consider three kinds of bidirectional conditionals and case expressions, whose expressions or paths are respectively source, view/non-source or normal variables.
The two special alignment statements update a source sequence using a view sequence. They receive a filtering source expressiones, and match
source elements satisfying es with view elements by position (alignpos)
or by keys (alignkey), defined by two source (ps) and view paths (pv).
Then, a bidirectional statement b processes matched source-view elements, a create statementc instructs how to create a suitable source to match with an unmatched view, and a recover statementr denotes how to process an unmatched source. Create statementsc are simply optional unidirectional updatesmu5. Arecover statement r is a unidirectional update of the form:
r::=ifethenr elser′ |delete|keepu
| casee ofpat~ →~r
It supports conditionals and case expressions like regular updates, and two primitive operations: delete, to delete an unmatched source; and keepu,
5
(◦<) : (τ1⇔Γτ2)→(τ2⇔Γτ3)→(τ1⇔Γτ3)
ifSthenelse : (τ1 →bool)→(τ1⇔Γτ2)→(τ1⇔Γτ2)→(τ1⇔Γτ2) unfork : (τ1⇔Γτ3)→(τ2⇔Γτ3)→(τ1, τ2⇔Γτ3)
ifVthenelse: (τ2 →bool)→(τ1⇔Γτ2)→(τ1⇔Γτ2)→(τ1⇔Γτ2) remfst : (τ2 →τ1)→(τ2⇔Γ(τ1, τ2))
withEnv : (Maybe τ1 →τ2 →Γ→Γ′)→(τ1⇔Γ′τ2)→(τ1⇔Γτ2) map : (τ1⇔Γτ2)→(τ1∗⇔Γτ2∗)
keep :τ⇔Γ() keepfst : (τ1, τ2)⇔Γτ2 keepsnd : (τ1, τ2)⇔Γτ1
alignpos : (τ1 →bool)→Maybe (Γ→τ2 →τ1)→(Γ→τ1 →Maybe τ1)
→(τ1⇔Γτ2)→(τ1∗⇔Γτ2∗) bot :τ1⇔Γτ2
alignkey : (Γ→τ1 →τk1)→(Γ→τ2 →τk2)→(τk1 →τk2 →bool)
id :τ⇔Γτ →(τ1 →bool)→Maybe (Γ→τ2 →τ1)→(Γ→τ1 →Maybeτ1)
→(τ1⇔Γτ2)→(τ1∗⇔Γτ2∗) in :n[τ]⇔Γτ
ifthenelse : (Γ→Maybe τ1 →τ2→bool)→(τ1⇔Γτ2)→(τ1⇔Γτ2)→(τ1⇔Γτ2) listeq :τ∗⇔
Γτ
Figure 10: Language of point-free lenses for translating core bidirectional updates (Complete in Appendix D).
to keep an unmatched source modified with u so that it does not satisfy the abovees filtering expression.
4.5 Core bidirectional lens language
To interpret our core language bidirectionally, we translate core bidirectional updates into a core language of “putback”-style lenses over generalized tree structures [28], supporting regular expression types. For the context of this paper, alens is a BXl:τs⇔Γτv between a source typeτs and a view typeτv
under an environment of type Γ, defined using the combinators from Figure 10. The concrete syntax for lenses is not essential in our design, and can be skipped unless for understanding the bidirectional update semantics discussed in Section 5. The intuition for each combinator (read as a transformation from view to source) should be understandable from its type signature, and more details regarding their concrete bidirectional semantics can be found in [28]6.
Each lens in the above language comprises two partial functions U : Γ→
6
Maybe τs → τv → τs and Q :τs → τv, satisfying laws similar to Update-Queryand QueryUpdate. Since these functions are partial, updating or querying may fail at runtime. This is sometimes inevitable, for instance, whenever a view value does not satisfy a view condition or a view depen-dency written in a WHERE VIEW clause. Remark that the update function
U receives an additional environment of type Γ and an optional source of typeMaybe τs (as in Haskell, but with short-hand notation Nothing =.and
Just v =v for values), to account for cases (like UNMATCHV clauses) when a new source must be reconstructed from the view without updating an existing source [5, 27]. For a lens polymorphic over its environment type, we often write justl :τs⇔τv.
4.6 XML subtyping and ambiguity
The notion of subtyping plays a crucial role in XML approaches with regular expression types. A typeτ1is said to be asubtype ofτ2, writtenτ1<:τ2, if the
flat values belonging toτ1 are also values of τ2, i.e.,Jτ1Kflat ⊆Jτ2Kflat. Under
a flat value representation, a value of a type naturally belongs simultaneously to all its supertypes. This motivates a notion of structural equality between types: two typesτ1andτ2 are equivalent (τ1=:τ2), meaning that they accept
the same set of flat values, if bothτ1<:τ2 andτ2<:τ1, e.g.,τ=:τ |τ. It also
induces an equivalence relation∼that ignores structure and relates values parsing the same data using different markup, formally,v ∼ v′ , flat(v) =
flat(v′), e.g.,L v ∼ R v.
A type τ is said to beunambiguous if the equivalence relation for struc-tured values of that type (∼τ) is the equality relation (=τ), intuitively meaning that there is only one way to parse a flat value of type τ into a structured value of typeτ. Unambiguous regular expression types have a direct correspondence to algebraic data types [29], and standard automata algorithms exist for deciding unambiguity of regular expression types in polynomial time [10, 31].
Since we retain a structured representation of values, upcasting a value
v1 of typeτ1 into a supertypeτ2 requires more than a proof of subtyping: we
must also changev1 into a valuev2 that contains the same flat information
as v1 but conforms to the structure of τ2. This problem has been
consid-ered in [23], that introduces a subtyping algorithm as a proof system with judgments of the form⊢ τ1 <:τ2 ⇒ c, that we treat as a “black box”. In
BX terms,c:τ2←→⊲ τ1 is called a canonizer [13], which is a bit like a lens
fromτ2 toτ1 that comprises a total upcast functionucast :τ1 →τ2, and a
partial downcast function dcast:τ2 → τ1. In our sense, canonizers satisfy
two properties stating that they only handle structure:
ucast v1 ∼ v1 Up∼
For an unambiguous type τ2, we can lift a canonizer c:τ1←→⊲ τ2 into a
well-behaved lens liftc:τ1⇔τ2. Similarly, for an unambiguous type τ1, the
inverse c−1 of a canonizerc:τ1←→⊲ τ2 —even though not a canonizer itself
due to partiality— can be lifted into a well-behaved lensliftc−1:τ2⇔τ1.
5
Type System and Staged Semantics
In traditional XML-based languages with regular expression types [17, 8, 9], the loose separation between types and values lends itself to a Curry-style interpretation: terms in the language are given semantics regardless of typing, and typing rules assess the well-formedness of terms. In BiFluX, however, types come prior to semantics, as an update program describes a BX between two known source and view types on which its meaning may naturally depend. This leads to a Church-style interpretation, where semantics is given to type derivations instead of independent terms. Also, as we have seen before, updates in our core language are given semantics in two stages: they are first interpreted as lens expressions (typed between given types), and lenses have themselves a bidirectional semantics.
5.1 Interpreting expressions, paths and patterns
The type system and semantics for expressions and paths is similar to that of µXQ [9] and Flux [8], adapted to our context. We merge typing and semantics into a single judgment Γ;mx ⊢ e:τ ⇒λγ.v, meaning “in type environment Γ with optional root variablemx, expression e has typeτ, and given environmentγ it evaluates to valuev”. Type soundness is guaranteed by construction, such that the argument environment γ is of type Γ and the producedv is of typeτ. The concrete rules can be found in Appendix A. We also define a judgment Γ;τ ⊢ e:τ′ ⇒λγ v.v′, meaning “in type environment Γ with root typeτ, expressione has typeτ′, and given environmentγ: Γ and root valuev:τ it evaluates to value v′:τ′”. The root type and underlying
value are added to the (type and value) environments under a fresh root variable:
Γ[x:τ];x ⊢ e:τ′⇒λv γ[x:=v].v′ x ∈/ dom(Γ) Γ;τ ⊢ e:τ′ ⇒λγv.v′
In BiFluX, we follow a simple approach to pattern matching. We first define pattern type inference as a judgment ⊢ pat :τ ⇒ Πτ that reads “pattern pat has type τ and yields a lens environment Πτ”. This is straightforward (Appendix B) since we require all pattern variables to be annotated with a type; many others, including [16, 32], have studied more advanced XML-based pattern type inference techniques. Alens environment
Πτ is a set of bindingsx := (l, τ′) of variables to lenses from a source type τ, such thatl:τ⇔τ′. As an abuse of notation, we see Π
we cast a source value v of typeτ into an environment of source variables
γv,Πτ ={xi :=Qi(v)|xi := (li, τi) ∈ Πτ}.
The second step for matching a pattern against an input value is to simply check for subtyping between the input type and the inferred pattern type [16], as the witness functions of our subtyping algorithm already give us a way to convert values in both directions. For ambiguous patterns that may match an input value in multiple ways, such functions are responsible for resolving the ambiguity. Different matching policies can be modelled by adapting the subtyping proof system, as noted in [23], despite not being essential for our approach.
5.2 Interpreting unidirectional updates
The typechecking and operational semantics of core unidirectional updates mimic those of the coreFluxlanguage. The judgment Γ ⊢ {τ}u {τ′} ⇒
λγv.v′ means that “in type environment Γ, a unidirectional update maps values of type τ to values of type τ′, and given environment γ and input value v (of type τ) it produces the updated value v′ (of type τ′)”. The
corresponding rules do not present any significant novelty and are relegated to Appendix C.
5.3 Interpreting bidirectional updates
Contrarily to unidirectional updates, that modify values from an input to an output type, bidirectional updates are evaluated against two given source and view types and return a lens between those types. The judgment Γ; Πτ ⊢ {τ} b {ν} ⇒ l indicates that “in type environment Γ and lens environment Πτ, a statementb produces a lensl (between source typeτ and view type ν under type environment Γ)”. The type environment Γ denotes normal variables (that are in scope of the update function of the generated lens); the lens environment Πτ denotes source variables from the source
τ; and the view type ν defines a view environment (also referred to as ν) that denotes view variables from the view ν. The dichotomy between our representations of source and view environments is justified by the need to keep a special account of view information: declared view variables must be used at least once in the update, while source variables might not be used at all to update the source. Most rules for typechecking and evaluating bidirectional updates as lenses are shown in Figure 11 and Figure 12. (The
listifyS and listifyV functions and the judgment⊢ τ1 6 τ2 ⇒ l will be
introduced in Section 5.4.)
Source/view expressions are interpreted under only a lens/view environ-ment: “in lens environment Πτ (and source type τ), a source expression
a value v:ν produces a value v′:τ′”.
Γ;x ⊢ e:τ′ ⇒λγv,Πτ[x:=v].v ′
Γ = Πτ[x:τ] x ∈/ vars(Πτ) Πτ⊢S e:τ′ ⇒λv.v′
Γν;· ⊢ e:τ′ ⇒λγv:ν.v′
ν⊢V e:τ′ ⇒λv.v′
Basic combinators The skipcombinator returns the lens that does not update the source if the view is the empty sequence, whilefail yields the bottom lens that always fails to update the source; replace completely replaces the source with a view that is “smaller”, such that the view type is a subtype of the source type.
Composition Bidirectional compositionb1;b2first splits the view into two
partsν1 andν2, evaluating b1 with viewν1 followed by s2 with viewν2 over
the same source. The auxiliary functionsplit(ν, θ1, θ2) = (ν1, ν2,l12) splits ν
such thatdom(ν1) =dom (ν)∩θ1 anddom(ν2) =dom (ν)∩θ2, returning a
lensl12: (ν1, ν2)⇔ν. Parallel lens composition (unforkl1 l2) is different from
sequential lens composition (l1◦<l2); for it to be well-behaved, the second
update can not affect the result of the first query, i.e.,Q1(U2(v,v2)) ⊑ Q1(v).
This property is currently checked dynamically byunfork, that fails to update the source otherwise. We believe that this check could be done at static time by combining recent work on XML query-update independence [2, 4, 6].
Changing source focus The bidirectional updatep[b] changes the source focus by traversing down the source path p, and then evaluates b with a fresh lens environment. Note that it is intrinsically different from the unidirectional update p[u], as the source type does not change and the source data is not updated in-place, but modified to embed the view data. Precisely, this requires interpreting the source path as a lens via a judgment Πτ⊢S {τ}p {τ′} ⇒l, that reads “in lens environment Πτ, path p changes the source focus from type τ to type τ′, and produces a lens l :τ⇔τ′” (Appendix F). Like inFlux, arbitrary paths can not be used to change the
source focus —as prescribed by the rules of Appendix F. For example, only theselfandchildaxes (and no absolute paths) are supported; this ensures that only descendants of the source focus can be selected as the new source focus and that a selection contains no overlapping elements. The iter b
operator shifts the source focus to all tree values in a source forest, and runs
b for each tree. Its corresponding BX will duplicate the view value for each source tree during updates, and enforce all selected source trees to be the same during queries.
view7. The judgment Γ⊢
V {τ}e {ν} ⇒l indicates that “in type
environ-ment Γ, expression e changes the view focus from type ν to type τ, and produces a lens l :τ⇔Γν” (Appendix G). Note that, to be successfully
interpreted as a “backward” lens, the expressione may only add information to the view, since all view information must be used to update the source; this implies that only a very restrictive class of injective paths —statically checked by the rules of Appendix G— can be used to change the view focus. The operationviewx :=e inb removes a view variablex from the current view environment without loss of information (with the view expression e
evidencing how x can be computed from the other view variables), followed by runningb.
Conditionals The conditional operationsifS,ifVandifchoose between two statementsb1 orb2 according to a boolean expressione, and differ subtly
on the bidirectional behavior of the underlying lenses (see [28]), given thate
is a source, view or normal expression. The same rationale is applied to case expressions (Appendix E).
Source-view alignment The alignment operationsalignposandalignkey
synchronize source and view forests. They 1) uniformize the source and view types into lists using listifyS and listifyV, 2) align source and view elements using matching algorithms [1] on lists by position or by keys —calculated as paths on the current source/view— and 3) run the
state-ment b for matching source/view pairs, the create statement c for un-matched source elements or the recover statement r for unmatched source elements. Create statements are interpreted unidirectionally using a judg-ment Γ⊢create{τ2}c{τ1} ⇒λmγ v2.v1, saying that “in type environment
Γ, a create statement c between source type τ1 and view type τ2 returns
an optional function (denoted by λm·.·) that given an environment γ: Γ and a view value v2 creates a source value v1”. In reverse direction, the judgment Γ⊢recover r {τ1} ⇒λγv1.mv1 states that “in type environment Γ,
a recover statementr for a source type τ1 returns a function that given an
environment γ: Γ and a source value v1:τ1 returns an optional recovered
source value mv1:Maybe τ1”. Note that our alignment operations receive a
source predicatee denoting which source values have a correspondence to view values; the underlying lenses enforce that newly created source values must satisfy e, while recovered source values do not originate from the view and must not satisfye.
Procedures Procedure calls P(p~s, ~ev, ~e) are interpreted under a new type
environment computed from the argument expressions~e. The new lens
envi-7
ronment is computed from the source pathsp~s, via a judgment Πτ⊢procS{τ}~p {νs} ⇒
l, and the new view environment is computed from the non-source expres-sions e~v via a judgment Γ⊢procV {νv} ~e {ν} ⇒ l. The semantics of a
BiFluX program is given by converting a set ∆ of procedure declarations
P(~x :~τ) :νs⇔νv , s into a set ∆⇔ of lenses P =l :νs⇔{x1:τ1,...,xn:τn}νv,
according to the following derivation:
{x1:τ1, . . . ,xn:τn} ∪νs ∪νv; Πνs ⊢ {νs}s {νv} ⇒l
f vs vv γ =γ ∪γvs:νs ∪γvv:νv
⊢ P(~x:~τ) :νs⇔νv , s ⇒P =withEnvf l
5.4 Type normalization
The semantics of our core language relies instrumentally on subtyping to match source and view types. The simplest example is the replace bidirec-tional update, that requires the view typeτ2 to be “smaller” than the source
type τ1 (Figure 11, Figure 12), according to a judgment ⊢ τ2 6 τ1 ⇒ l
that returns as evidence a lens l :τ1⇔τ2. As the reader may guess, we
could compute ⊢ τ2 6 τ1 ⇒ l by checking for subtyping between τ2 and
τ1 (⊢ τ2 <:τ1 ⇒ c) and lifting the resulting canonizer into a lens. But,
before doing so, we must verify that: the view type τ2 is unambiguous, a
requirement to liftc into a lensliftc; and the source typeτ1 is unambiguous,
since theucast function of the canonizer does not consider the original source and a naive implementation of an update would potentially discard source information projected away by the lens.
As an example, recapitulate the source database of books used in Section 2 and imagine how we could evaluate a simple update:
REPLACE $source/books/book/title WITH $view
using a listtitle[string]∗ as the view type. Consistently with the unidirec-tional semantics for paths (Appendix A), the evaluation of the source path as a lens traverses down the source tree and keeps only titles, destroying element la-bels and replacing all authors for the empty sequence, and modifies the source focus to the intermediate type (title[string],(),()∗)∗. Then replace checks for subtyping between the view type and the intermediate type, producing a mediating canonizer. Since the intermediate type is ambiguous, the upcasting function of the canonizer would translate a view sequence [title["mybook"]] into an intermediate value [(title["mybook"],((),[ ]))], that would in turn lead to an updated sourcebooks[[book[(title["mybook"],(aut1,[ ]))]]]. This is
clearly unsatisfactory as it would discard the entire book database except the first authoraut1 of the first book!
Source and view normalization To avoid these problems, we introduce
unambiguous ones while carefully preserving the original markup informa-tion that keeps trace of hidden informainforma-tion. Namely, we define a source normalization procedure normS(τ) = (τ′,l), that normalizes a source type into an unambiguous subtype τ′ together with a lensl :τ⇔τ′, and aview
normalization procedure normV(τ) = (τ′,l), that normalizes a view type into an unambiguous subtype typeτ′ together with a lens l:τ⇔τ′. Their main difference is that they compute lenses in opposite directions, suggest-ing that source normalization may abstract ambiguous information (like redundant choices) while view normalization may not. Their definitions are shown in Appendix H. We do not claim that our normalization procedures are complete, in the sense that they can disambiguate any ambiguous type, but when they (statically) do succeed the normalized types are unambiguous. In a nutshell, we try to normalize a source type using automata reduction techniques [10, 31], and derive a lens between the ambiguous and unambigu-ous types; we only normalize view types into isomorphic types. Furthermore, we evaluate source paths in a two-phased semantics: a path is interpreted as a completely information-preserving lens, that just marks unselected source typesτ with a special tag τ instead of replacing them for the empty se-quence (Appendix F); and tagged types are to be removed during source normalization, that already requires special handling anyway.
Normalized subtyping and listification We are now ready to safely
defineτ1 6 τ2 as the following judgment:
normS(τ2) = (τ2′, l2) normV(τ1) = (τ1′, l1) ⊢ τ1′ <:τ2′ ⇒c
⊢ τ1 6 τ2 ⇒l1◦<liftc◦<l2
Unlike iteration for unidirectional updates, that changes the focus to all the atomic elements in a forest and updates their values (and types!) inde-pendently, bidirectional iteration is type-preserving and involves updating a source sequence with view information and somehow fitting it back into a shape that conforms to the source type. Since shape alignment is an intractable problem for arbitrary source and view types [27], we uniformize source and view types into lists of (choices of) atomic types according to two functions:
elems(τ′) ={α1, . . . , αn} (α0 |. . .|αn)∗ unambiguous
normS(τ) = (τ′,l) ⊢ τ′<: (α
0 |. . .|αn)∗ ⇒c
listifyS(τ) = ((α0|. . .|αn),l◦<liftc−1)
elems(τ′) ={α0, . . . , αn} (α0 |. . .|αn)∗ unambiguous
normV(τ) = (τ′,l) ⊢ τ′<: (α0 |. . .|αn)∗ ⇒c
listifyV(τ) = ((α0 |. . .|αn),liftc◦<l)
type. While this does not pose a problem with the for-each semantics of plural high-level updates, it may lead to runtime errors forUPDATE FOR VIEW updates over intricate structures. An alternative is to statically check for type equivalence inlistifyS, supporting only pure source lists. The function
elems :Type → {Atom} returns the set of atomic types in a sequence type.
6
BiFluX to Core Update Normalization
In this section, we formalize the translation from the high-level BiFluX
language to the core language presented in Section 4, highlighting the signifi-cant gap between them. This process is usually referred to as normalization
in languages like XQuery and Flux. We define two main normalization functions that interpret statements as bidirectionalJ|||| − ||||Kb
Stmt and unidirec-tional updatesJ|||| − ||||Ku
Stmt. Most translation rules are straightforward and a few interesting ones are shown in Figure 13; the complete set can be found in Appendix I. Simple bidirectional updates are translated by a function J
|||| − ||||Kb
U pd(es,ev, ~x =~e), where the extra parameters group the WHEREclauses
of the update into a source selection expressiones, a view selection expression
ev and a sequence of view bindings~x =~e; these triples are parsed from a set
of conditions, according to their source/view tags, by a function J|||| − ||||KConds. Simple unidirectional updates are translated by a functionJ|||| − ||||Ku
U pd(e), where
e is the conjunction of all theWHERE clauses of the update.
For specialUPDATE FOR VIEWstatements, thesplitVStmt function parses aVStmt into a matching statement and two optional unmatched-view and unmatched-source statements. Optional unmatched-view statements are translated using a function J|||| − ||||Kc
MStmt(mpat) that takes an extra optional
view pattern and returns a core create update; if no UNMATCHV clause is defined, the U function of the underlying lens will be evaluated without an original source. Optional unmatched-source statements are translated using a functionJ|||| − ||||KrMStmt(mpat) that takes an extra optional source pattern and returns a core recover update; if noUNMATCHSclause is defined, all unmatched source elements are deleted by default.
The translation denotes a partial function from high-levelBiFluXto core
7
Related Work
XML update languages Several XML update languages have been
pro-posed, including (among many others) XQuery! [15], Flux [8] and the standard W3C XQuery Update Facility [30]. Even though the specification style, expressiveness and semantics of the XML updates that can be written may vary significantly, they all focus on updating XML documents in-place, i.e., updating selected parts of an XML document, keeping the remaining parts of the document unchanged. This means that update programs can be seen as unidirectional transformations that insert, delete or replace elements in a source document and produce an updated document conforming to a new target type. XML Updates in BiFluX are different in that they determine how to update a source document (using some view information) while preserving its source type. This poses different (BX-related) challenges on how to deal with non-in-place updates (likeUPDATE FOR VIEWstatements that may change the cardinality of a sequence instead of updating each element), and therefore how to modify the remaining parts of the source document (e.g., by changing branching decisions) to accommodate the new data so that the updated source fits into the same type.
XML view updating In [12], the author studies the problem of updating XML views of relational databases by translating view updates written in the XQuery Update Facility into embedded SQL updates. The work of [22] supports updatable views of XML data by giving a bidirectional semantics to the XQuery Core language. The semantic bidirectionalization technique of [25] interprets various XQuery use cases as BXs by encoding them as polymorphic Haskell functions. The Multifocal language [26] allows writing high-level generic XML views that can be applied to multiple XML schemas, producing a view schema and a lens conforming to the schemas. In the four approaches, the programmer writes a view function and the system derives a suitable view update translation strategy using built-in techniques that he can not configure. InBiFluX, he writes an update translation strategy directly as an update (over the source) and the system derives the uniquely related query.
XML bidirectional languages Many bidirectional programming
choice of combinators, lens languages can become very powerful at specifying application-specific behavior [28, 1, 27]. However, their lower-level nature also induces a more cumbersome programming style that makes it impractical and often unintuitive for users to build non-trivial BXs by piping together several small, surgical steps.
BiFluX features a new programming by update paradigm, that enables the high-level syntax of relational languages such as XSugar and biXid while providing a handful of intuitive update strategies. Remember the huge gap between our high-levelBiFluXlanguage (variables, procedures) and the core lens language that gives it semantics (canonical “point-free” combinators). In [18], we have proposed a simple treeless functional language for writing totalput (or update) functions, such that existence of a well-behaved lens can be checked statically, and corresponding totalget (or query) functions can be derived automatically. The most significant and innovative difference inBiFluX is again the declarative surface language used to specify BXs as bidirectional update programs, at a notably higher-level of abstraction than nativeputfunctions. BiFluX programs may however be partial, due to the added expressiveness of our language.
Quotient lenses [13] propose loosening lenses modulo equivalence relations, for easing the processing of ad-hoc data formats. To enable compositional reasoning, most interesting quotient lens combinators (concatenation, union, iteration) require the equivalence relations to be decomposable. At first glance, we could lift our core lens language into quotient lenses to allow seamless composition with (subtyping) canonizers. However, since our notion of equivalence is not decomposable for ambiguous types, this would not overcome the need for our type normalization procedures.
8
Conclusions
In this paper, we propose a novel bidirectional programming by update
paradigm that comes to light from the idea of extending a traditional update language with bidirectional features. Under the new paradigm, programmers write bidirectional updates that specify how to update a source document to reflect additional view information. We substantiate with examples that this enjoys a better tradeoff between the expressiveness and declarativeness of the written bidirectional programs, by allowing users to write directly, in a friendly notation and at a nice level of abstraction, a view update translation strategy that bundles all the pieces to build a BX.
To demonstrate the potential of this paradigm, we designed BiFluX, a type-safe high-level bidirectional XML update language. We have fully implemented BiFluX in Haskell and the code, together with additional examples, is available from the project’s website8. Our tool translates source
8
and view DTDs into Haskell type declarations using the HaXml package9,
and interprets bidirectional updates as bidirectional lens transformations between the given schemas in a robust manner: the implementation of the core-to-lens translation is strongly-typed, serving as a proof of soundness that helped us catching early programming errors at compile-time; and the bidirectional semantics is completely guided by an underlying lens language, whose correctness has been shown separately in [28]. To support a flexible design, with arbitrary conditionals, case statements and expressions, the stat-ically generated lenses may undergo runtime checks (for particular source and view documents) to ensure that the underlying update and query functions are well-behaved.
As future work, we plan to provide more static guarantees toBiFluX
by incorporating existing path-query static analyses, implement more pow-erful pattern type inference algorithms to avoid excessive annotations, and extend the class of bidirectional updates that can be written by integrating user-defined lenses for defining source and view foci. We also plan to im-prove the efficiency of our prototype for large XML databases by exploring optimizations to the underlying lens language, including incremental update translation. To empirically study the practical impact of BiFluX, we are currently undergoing a larger model-based code testing use case.
References
[1] D. M. J. Barbosa, J. Cretin, J. N. Foster, M. Greenberg, and B. C. Pierce. Matching lenses: alignment and view update. In ICFP 2010, pages 193–204. ACM, 2010.
[2] M. Benedikt and J. Cheney. Destabilizers and independence of XML updates. Proc. VLDB Endow., 3(1-2):906–917, 2010.
[3] V. Benzaken, G. Castagna, and A. Frisch. CDuce: an XML-centric general-purpose language. In ICFP 2003, pages 51–63. ACM, 2003.
[4] N. Bidoit, D. Colazzo, and F. Ulliana. Type-based detection of XML query-update independence. Proc. VLDB Endow., 5(9):872–883, 2012.
[5] A. Bohannon, J. N. Foster, B. C. Pierce, A. Pilkiewicz, and A. Schmitt. Boomerang: resourceful lenses for string data. In POPL 2008, pages 407–419. ACM, 2008.
[6] S. Bottcher. Testing intersection of XPath expressions under DTDs. In
IDEAS 2004, pages 401–406. IEEE, 2004.
9